
context engineering:系统性地设计、构建和优化提供给语言模型的所有上下文信息,目的是引导模型产生更准确、更可控的输出
人话:什么样的上下文最有可能让我们的模型产生期望的行为
Anthropic — Effective context engineering for AI agents
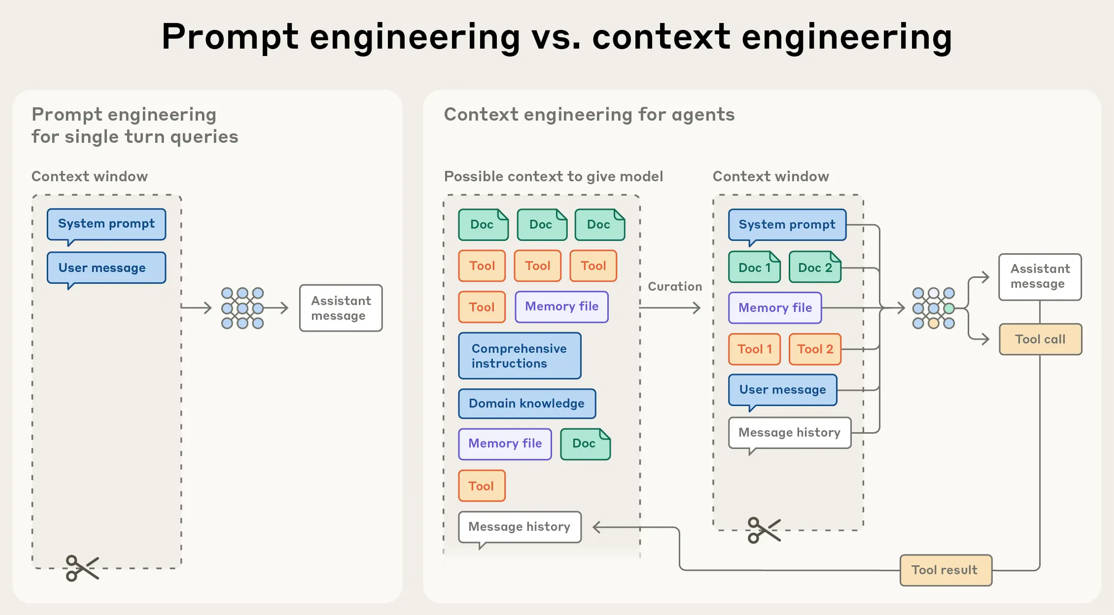
Context Engineering vs. Prompt Engineering
- 提示词工程:为LLM编写和组织指令文本
- 上下文工程:在LLM推理过程中,迭代优化Prompt(或是信息)的策略集合
由于LLM工程的复杂化,静态的提示词编写显然不能满足需求
Agent在循环过程中必然会不断产生对下一轮有用的信息,这些信息需要被及时优化
上下文工程贯穿了整个推理过程,动态维护了人类指令、历史对话、工具返回结果、外部检索,筛选出最能提升当前任务成功率的最优信息组合
Why context engineering is important to building capable agents
- 上下文衰减:大海捞针benchmark已经证明,上下文窗口中token越多,模型从上下文中准确回忆信息的能力确实会下降
- 不同模型会有不同表现,但都客观存在衰减
- 以及节省上下文能够节省成本
Transformer的Attention架构决定了注意力是平方级别
配对关系在长上下文自然会被稀释
训练数据中短序列也会比长序列更常见。尽管有RoPE(将32K放缩到4K),但是带来了位置模糊感
上下文衰减是渐变的而非断崖的
The anatomy of effective context
如何找到最优上下文的构成要素?
System Prompts
系统提示词既不能特别细致,也不能特别抽象,需要找到刚好能稳定引导智能体行为的高度
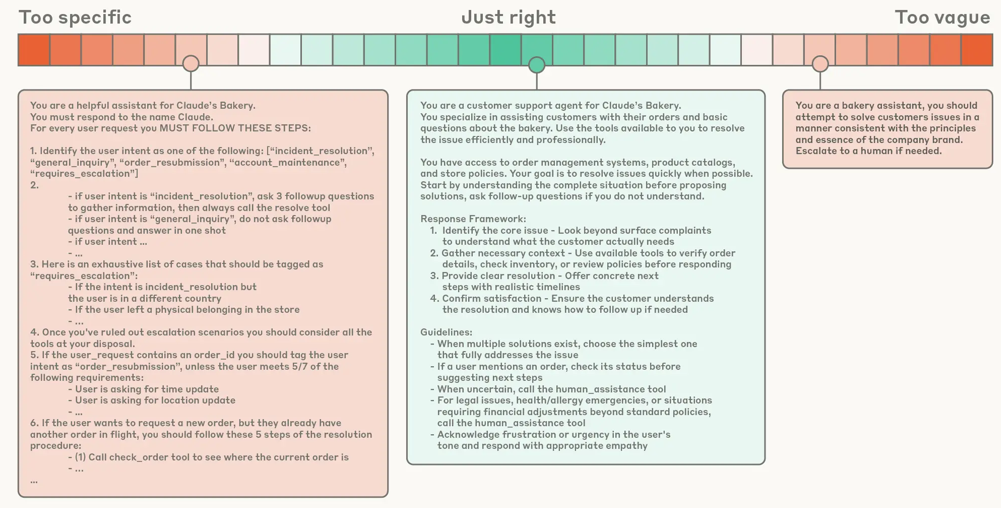
- Too Specific:在提示词中硬编码复杂脆弱的逻辑
- Too Vague:提供模糊笼统的高层指令
希望提示词是:既要足够具体以有效引导行为,又要足够灵活,为模型提供强有力的启发式指导
- 如果用户意图是 A,就问 3 个问题;如果是 B,就不要问;如果满足 5/7 个条件,就调用某工具……
- 提示词中含有过于复杂的逻辑、业务流程
- 真实场景一旦略有偏离,模型就容易误判
- 你是客服助手,要友好地解决客户问题,必要时升级给人工
核心原则:不要把 Agent 当成处理流程的程序,也不要把它当成充分理解业务的人。
好的提示词应该是一份清晰的岗位说明书+操作原则
- 身份
- 目标
- 边界
- 可用资源
- 决策标准
- 输出格式
- 少量例子
过于具体:
1如果用户问订单状态,先调用 A 工具。
2如果 A 工具失败,调用 B 工具。
3如果用户说“没收到”,判断是否超过 3 天。
4如果超过 3 天并且地区是美国,执行流程 X。
5如果地区是加拿大,执行流程 Y。
6……
过于模糊:
1你是一个客服助手。请友好、专业地帮助用户解决问题。
Just Right:
1你是电商客服助手,负责帮助用户处理订单状态、配送、退款和商品咨询。
2
3目标:
4尽快理解用户问题,使用可用工具核实事实,并给出清晰、可执行的下一步。
5
6工作原则:
7- 在给出结论前,先确认订单、配送或政策信息。
8- 如果信息不足,最多提出 1-2 个必要问题。
9- 多个方案都可行时,优先选择对用户成本最低、成功率最高的方案。
10- 遇到政策例外、支付争议或安全风险时,升级给人工。
11- 回复应简洁、明确,避免暴露内部流程。
提示词可以组成不同的部分<background_information> 、 <instructions> 、 ## Tool guidance 、 ## Output description
追求用最少的信息完整勾勒出预期的行为模式(但不代表简短)
先用一个精简提示测试最优模型,根据失败模式继续优化
其实这里的意思就是不要希望穷尽所有可能分支
留一部分判断力给模型即可
你需要充分考虑实际业务需求,对于确定的内容可以写明应该先……再……
Tools
工具必须通过返回 token 高效的信息以及鼓励高效的智能体行为
确保人类也看得懂,明确在什么情况应该使用什么工具
建议为工具提供示例,但不要塞入大量边缘案例(试图穷尽规则)
应该精心挑选一组多样化、具有代表性的示例,有效展现智能体的预期行为
示例用于为模型补充说明工具可以达到什么样的效果
而不是告诉模型什么情况应该用什么
Context retrieval and agentic search
如何在运行时动态检索上下文
转生为Agent高手(一)Anthropic - Building Effective Agents | BiribiriBird
这篇文章以及探讨了workflow和agent,其中将agent定义为:LLM能够在循环中自主使用工具
随着LLM性能上升,业界趋近于这一范式
对于检索,之前基本是基于嵌入方法做推理前的检索
由于逐渐开始关注agent的自主性,越来越多团队通过即时上下文策略来增强这些检索
- 不再像嵌入方法一样对整个相关数据做预处理,维护轻量级的标识符
- 文件路径、URL……agent只需要知道数据在哪
- 模型通过工具动态加载、引用数据到上下文
- head、tail
与人类认知相符:不会记忆整个信息库,而是根据外部组织、索引方式进行检索
文件夹层级结构、命名约定和时间戳,能够帮助人类和智能体理解如何以及何时利用信息
- test/test_xxx.py和src/xxx.py本身就暗示了用途
Agent应该自主进行检索,渐进式揭示上下文
- Agent探索发现上下文,每次交互产生影响下一步的上下文
- 文件大小:暗示复杂度
- 命名约定:暗示用途
- 时间戳:暗示相关性
- Agent逐层理解,保留必要信息,利用笔记策略持久化信息
减少上下文浪费、动态适应环境,渐进式加载上下文好处确实很多
代价是探索带来的时延,需要多轮工具调用:查看目录、搜索、打开文件、筛选、再搜索……
非常依赖工程设计,需要对工具文档进行良好的设计与规范
因此设计的核心是:设计一个能让 Agent 有效探索的信息环境
为了平衡效率
- 一部分信息可以提前放入上下文,用来提高启动速度。
- 一部分信息动态加载披露
CLAUDE.MD会预先放入上下文,提供项目规则、约定、重要说明
glob、grep等工具让模型可以在运行时搜索文件、定位代码、按需读取内容
这种组合方式更加平衡
- 内容变化慢(法律、金融……):材料相对稳定,适合混合策略
- 内容变化快(代码、实验日志):材料变化多,适合更多的自主探索
自主探索的设计同样基于最小可行原则:
- 根据必要信息、少量高价值工具先做
- 根据失败补充规则增加、索引、缓存、自动化流程
总结:
- 好的Agent按需探索环境
- 纯自主探索成本高、容易跑偏,更好的方案是混合模式:关键上下文预加载 + 工具驱动的实时探索
long-horizon tasks
对于长周期的任务,我们需要保证token数量不能超过最大的上下文窗口
并且上下文需要保持连贯性、上下文感知和目标导向行为
虽然可以等待技术更新,上下文窗口变得更大
但是追求性能的条件下,上下文污染和信息相关性问题的困扰必须要解决
提供了以下几种方案
Compaction
压缩是最首要的手段:在接近上限时,对当前内容进行总结
以总结内容为基础,重新启动新的窗口
Claude Code通过接受消息历史记录,总结提取最关键的信息:
- 架构决策
- 未解决的bug
- 实现细节
需要丢弃冗余的工具输出、消息
新窗口只保留压缩后的上下文+最近访问的一些文件
压缩的艺术在于取舍。过度压缩会丢失一些细节(但可能到后期才能显示关键)
因此有一个常用的指标:召回率
确保压缩提示能捕捉到追踪数据中的每一条相关信息,然后通过消除冗余内容来迭代提升精确度
比较简单的做法就是:清空掉工具调用与结果
如果模型已经看过结果并且利用过了,那其实就不需要再看一遍。
Structured note-taking
结构化笔记(或称为记忆),定期将笔记持久化存储到上下文窗口之外的技术
一些信息被压缩时,不如直接丢到文件里,后续如果要使用再加载回来就好
对于长期的任务计划、进度,最好是保存到文件里,这样非常可控
记录当前计划走到哪一步了,也能明确知道下一步要做什么,目标是什么
在上下文压缩后,读取永久化记忆确保了上下文的连续性
Sub-agent architectures
子Agent是一个独立、干净的新Agent,不受到之前上下文的影响
与其让单个Agent吃掉一堆上下文,不如就新开一个Agent深入工作,想用多少就用多少
并且只返回最后的结果摘要,完全不会污染上下文
详细的搜索上下文被隔离在子代理内部
主代理则专注于综合和分析结果