
Anthropic — How we built our multi-agent research system
Don’t Build Multi-Agents | Cognition
这次我们同时看两篇文章,进行对照
Intro
reseach型任务的特点:
- 很难提前预测所需的步骤
- 无法有既定的路线,在探索过程中的思路涌现会带来新的分支
这类任务需要从海量的信息中搜索出关键内容(本质是压缩)
- 串行的单Agent的上下文与工具调用很难支持完成整个任务
- 多Agent系统支持单个Agent用更干净、更充分的上下文窗口去处理分支任务
因此多Agent系统在此类任务中能够呈现惊人的性能提升
缺点是:消耗了更加大量的token、进行了更多轮次的工具调用
但这也是性能提升的核心原因
总结:
- 需要高度并行
- 信息量超过单次上下文窗口
- 需要对接大量复杂工具
- 所有Agent涉及的上下文重叠较小、无复杂依赖关系
这个时候推荐使用多Agent
Architecture
设计一个Research Agent System
采用orchestrator-worker模式
- 主导Agent协调整个流程
- 任务运作交由专门子智能体
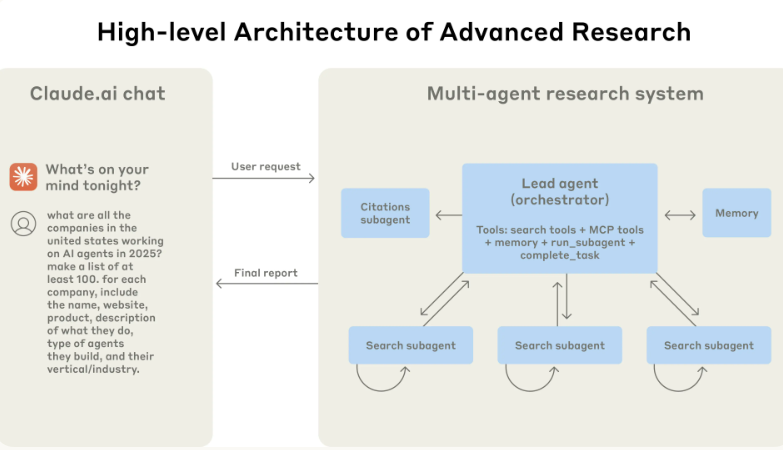
用户需求:调研100家2025年美国的AI Agent公司,给出列表
- Lead Agent分析查询、制定策略,生成subagents探索
- subagents迭代使用搜索工具收集信息,并且完成过滤,返回lead agent
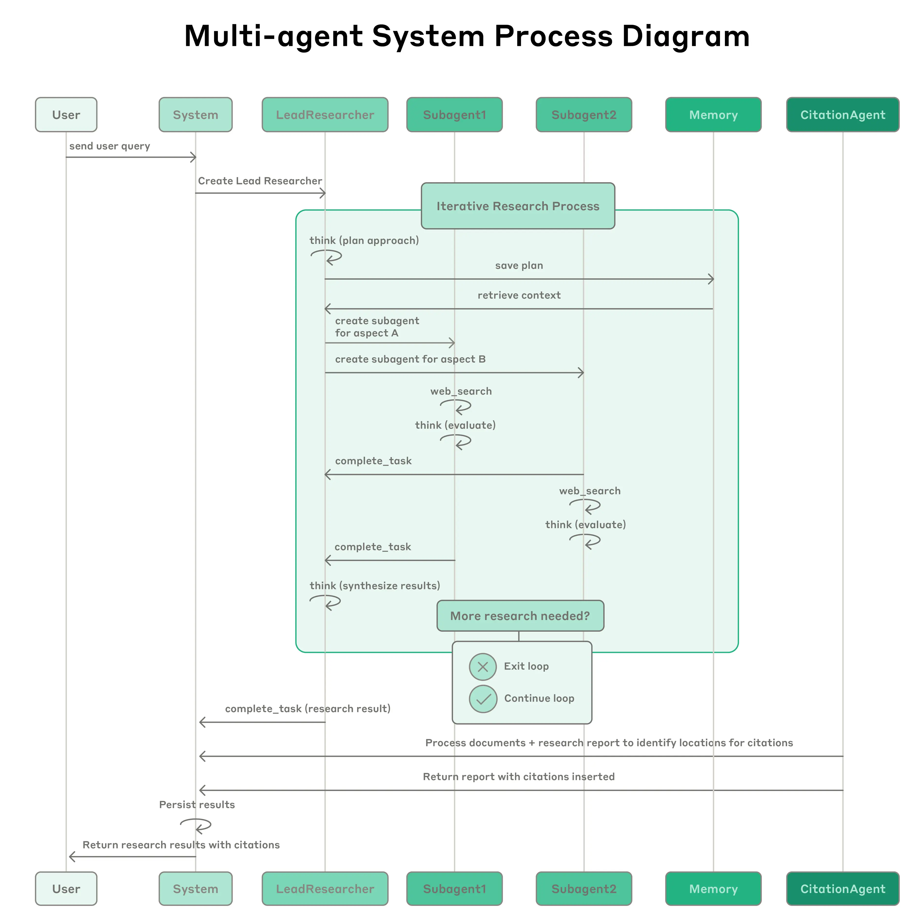
- User->System:创建一个Lead Reseacher,进行迭代Process
- Iterative Research Process
- think进行planing,将plan保存到memory中(创建or修改)
- 检索memory,避免plan丢失
- 创建subagents,内部进行独立的搜索与评估
- 返回压缩后的结果
- Lead评估是否足够,否则继续调研
Prompt
多agent相对于单Agent的协调复杂度急剧增加
每个Agent都是由Prompt驱动的,因此需要注意Prompt的一些原则
- 为每一个Agent构建完全相同的提示词+工具做模拟环境测试,理解工作过程
- Lead需要为每个subagent清晰分配任务,防止重复劳动与遗漏
- 提供明确目标、输出格式、工具、资源使用指南、清晰任务边界
- 根据问题难度自动控制投入的资源(多少个Agent、多少次工具调用)
- 直接在Lead Agent中的Prompt写明资源分配规则
- 例如
- 简单事实查询(xxx家CEO是谁):1个Agent3-10次Tool Calls
- 直接对比类任务(比较 Claude 和 Gemini 的企业功能差异):2-4个Agent,每个Agent负责一个维度,每个Agent需要10-15次Tool Call
- 复杂研究问题(分析 AI 编程助手市场格局、主要玩家、商业模式、技术趋势和未来机会):超过10个
- 在Prompt中添加启发式的工具使用原则
- 正确的工具选择非常重要,MCP带来了海量工具,造成了困难
- 启发式规则
- 首先检查所有可用工具
- 根据用户意图匹配工具
- 广泛的外部探索搜索网络or优先使用专用工具而非通用工具
- 优先确保工具描述质量
- Agent本身建议参与优化过程
- Agent改自己的Prompt、测试工具问题、分析失败案例都很擅长
- 用Agent来改进Agent的工作环境
- 先广泛搜索再逐步聚焦
- 通过提示词要求Agent先从简短的、宽泛的查询开始
- 评估可用信息,缩小范围
- 抵抗Agent偏好冗长、具体的查询
- 显式引导Agent怎么思考,高效利用thinking token
- Lead Agent主要思考如何管理任务,subagent主要思考工具怎么交替使用
- 结构化思考流程
- 先规划,再调用工具
- 看完工具结果后再评估、补缺、调整下一步
- 并行工具调用
- 主智能体并行启动 3-5 个子智能体,而非串行执行
- 子智能体同时使用 3 个以上工具
评估
Agent达成目的路线完全不确定
早期 · 小样本
早期上升空间巨大,一个提示词调整可能30%到80%
早期构建的时候准备20个真实查询进行测试即可
不要为了构建完整评估体系才开始行动
LLM-AS-JUDGE
- 事实准确性(主张是否与来源一致?)
- 引用准确性(引用的来源是否支持主张?)
- 完整性(是否涵盖所有要求方面?)
- 来源质量(是否优先使用一手资料而非低质量的二手资料?)
- 工具效率(是否以合理次数使用正确工具?)
Antropic发现单一提示词输出0.0-1.0分数or正负分类
与人工判断的一致性最高
当存在明确答案的时候,使用LLM评测非常有效
只需要判断与答案是否一致即可
Human Eval
人工测试能够帮助发现一些偏差,因此必不可少
人类似乎更喜欢SEO优化得到的内容,而不是一些个人博客
因此可以通过这个偏好去调整提示词
Production reliability
Agent错误
- 需要做持续化执行,存到本地,防止错误重新开始
- 中断点恢复,根据持续化的存储结果继续工作
- Agent参与错误处理:告诉错误信息,让模型更换路线
- 确定性的保护措施:失败后自动retry、定期做check
调试:Agent中间路径不确定
- full production tracing(完整的生产追踪)
- 传统指标:延迟、错误率、CPU、内存
- 结构化信息:决策记录、工具记录、任务分派记录、失败记录、重试记录
- full production tracing(完整的生产追踪)
部署
- 新版本代码部署的时候很难逐步替换旧版本代码(智能体可能正在运行)
- rainbow deployments:新旧版本同时运行,但是新来的流量导入到新版本,直到旧版本Agent没有调用
同步
- Lead Agent需要等待所有subagent完成任务
- asynchronous execution
- Lead边接受边调整方向,必要时动态创建
- 但确实会更难协调、容易冲突
Avoid
基于cognition.ai这一篇文章
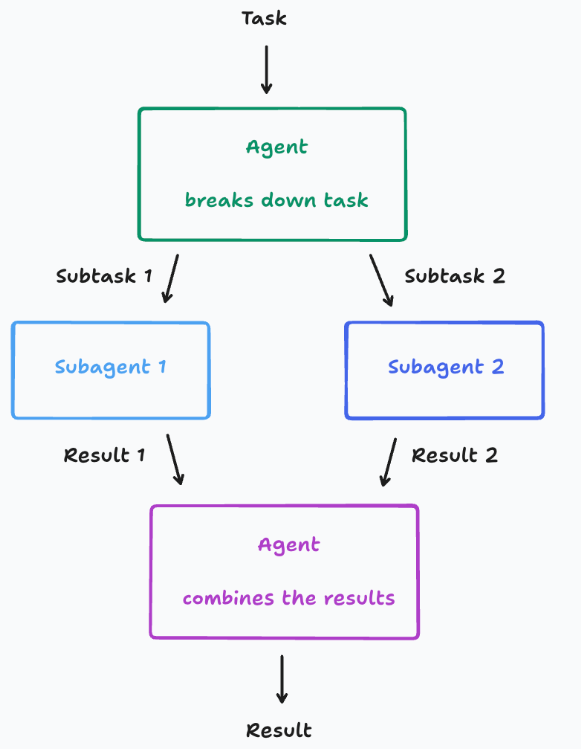
常见的多Agent范式如图,但是这种架构非常脆弱
任务:抄袭一个《Flappy Bird》
- 子任务1:构建一个带有绿色管道和碰撞箱的动态游戏背景
- 子任务2:构建一只可以上下移动的小鸟
结果
- 子任务1:建一个看起来像《超级马里奥兄弟》的背景
- 子任务2:构建了不像游戏素材的鸟
最终Lead Agent将错误内容完成合并
这个问题并不能通过简单的将原始任务中的上下文完全塞给subagent解决
注意,对话是多轮的,subagent需要自己去调用工具
任何细节差异都可能带来对任务不同的理解
Principle
- Principle1:完整的上下文轨迹必须共享
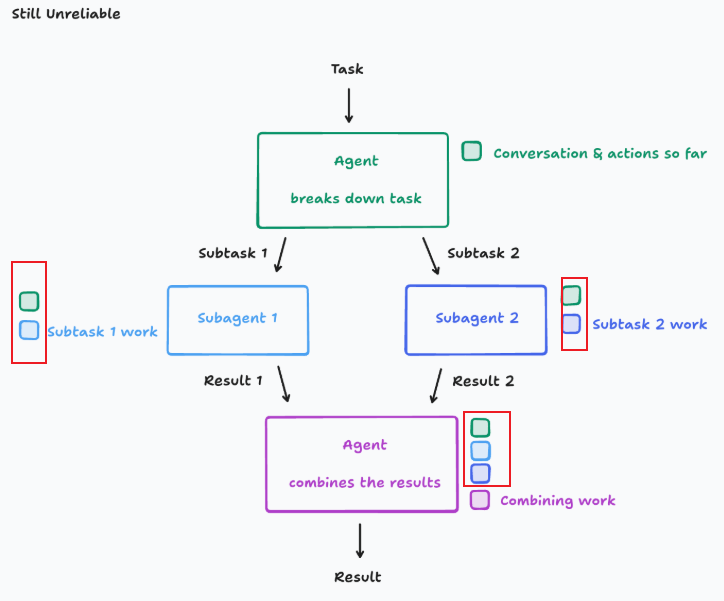
- Principle2:行动隐含决策
Agent的所有行动中自然包含了丰富的信息,若造成丢失则很有可能带来错误积累
MultiAgent并不能保证上述两个原则
最简单的方式只有:单线程的线性智能体
但是上一篇文章也提到了,单智能体会受限于上下文窗口的限制,性能也会触碰瓶颈
但我们显然可以通过压缩,尽量去保证上下文连续性
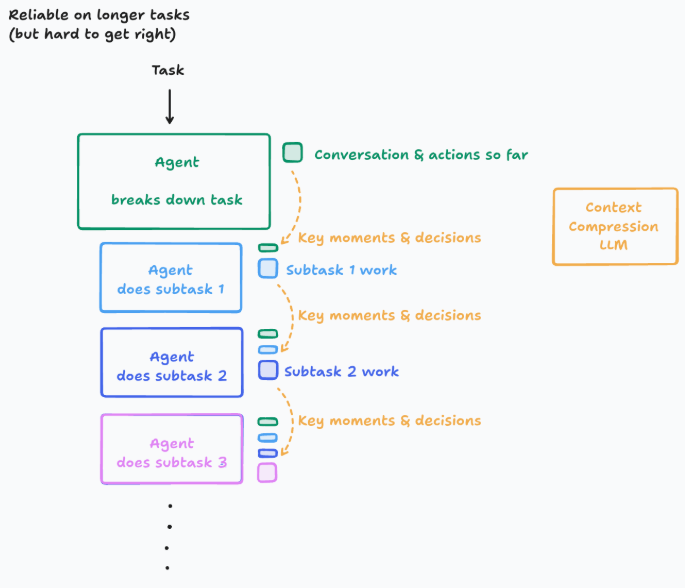
- 引入一个专门用来压缩上下文的LLM
因此:能不使用MultiAgent,就不要使用
需要衡量场景的可靠性是否大于并行性
Applying the Principles
如果无法完成两个原则的落实,则必须要考虑:
- 谨慎地决定哪些工作可以拆出去,哪些不能拆
例如:
- Claude Code设计的subagent只用来回答问题
- 暗示:调查型任务可以拆出去,决策型/执行型任务要谨慎拆出去
- Edit Apply Models:大模型负责“决定怎么改”,小模型负责“实际应用修改”
- 这种架构实际上非常高危:只要解释里有轻微歧义,小模型就可能误解并改错
- 建议:同一模型先决定怎么改,然后顺着上下文直接完成修改
- 暗示:不要把一个高度依赖上下文的决策链切成两个互相误解的环节
- 除非提供非常详细的指导
- Multi-Agents:如果仍然需要并行性,则需要解决Agent之间及时沟通的问题
- cross-agent context-passing(跨Agent上下文传递)目前能力一般
- 建议:长期看好,短期不建议作为生产级默认架构
但是这些建议是跟随时代变化的